Adaptive Query Joins
Published: Jul 26, 2026
This is a new feature added into SQL Server 2017 to try and alleviate the pain of an age old problem… parameter sniffing.
For anyone who doesn’t know what this is, I have outlined the problem with a couple of examples in the previous post, therefore have a quick read through… but if you’re already aware of the problem then read on…
First things first, there’s a HUGE caveat I need to mention here… in SQL Server 2017 an Adaptive Query Join will ONLY occur if the query is in BATCH mode. This means that a Columnstore MUST be present somewhere in the query.
However, in SQL Server 2019 (currently in CTP 2.2), BATCH mode can be used without a Columnstore present. It is now viable for all (a lot of) iterators.
On my Surface, which I’m currently coding against, I don’t have 2019 installed and therefore to get the join to occur I’ve had to create a copy of my SalesOrderHeader table and columnstore it:
So… now let’s run a query which has a large variance data (for which I’m using the query from the previous blog… linking Sales to SalesPersonID, but this time via a join because a direct query on the table no longer has the desired effect due to the Columnstore):
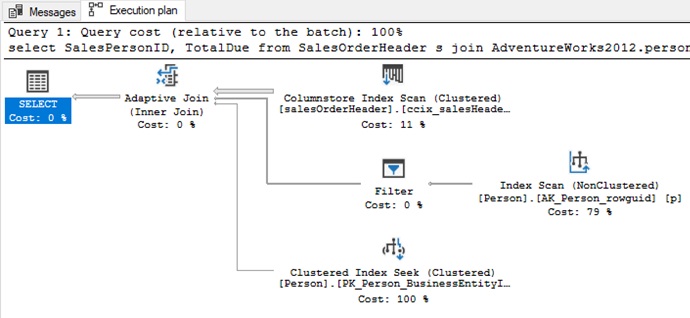
And there we are… the Adaptive Join. So… what is it?
It’s basically BOTH a Nested Loop and a Hash join in one. What happens is that the Query Optimizer knows that there’s variance in the data and therefore it gives itself options by creating this execution plan, catering for both options in one.
What happens upon execution is that the query starts running without deciding which direction it’s heading… it reads records from the Input (ie. The columnstore in the plan above) and if it is happy there is only a few records coming out then it uses a Nested Loop… but if the stream of records coming in seems large, it uses the Hash.
This, therefore, attempts to remove our performance issues around parameter sniffing. It’s not perfect (the cutoff for choosing each option may not be perfect) but it does alleviate the problem to a large degree.
Couple of notes:
How do you know which has been used at execution time? The execution plan will let you know:

As per the above, you can see that the estimated plan was that it would use a Hash and, upon running, it did indeed use a Hash match.
Changing the query slightly will give us the other option:

Bingo.
So, lastly… why is it that we can only see this join using Batch mode? It’s a logical answer actually… in Execution Plans, records are streamed one at a time (from right to left in the visual plan). Therefore it would be cumbersome to re-write the optimizer to work in a different way by streaming records until it could make a decision on the join type. However, in Batch mode SQL Server streams batches of rows (just under 1000 in each batch)… therefore just one batch and it can make a decent guess as to what choice to make. That fits with the way the Optimizer works… one single “GET” command to the first operator in the plan (from right to left again) and it can make a choice… no blocking and no heavy re-writes of internal Optimizer code.
Therefore we need Batch mode for this to appear. As mentioned, in SQL Server 2017 this requires a Columnstore, but in SQL Server 2019 this pretty much comes as standard.
For anyone who doesn’t know what this is, I have outlined the problem with a couple of examples in the previous post, therefore have a quick read through… but if you’re already aware of the problem then read on…
First things first, there’s a HUGE caveat I need to mention here… in SQL Server 2017 an Adaptive Query Join will ONLY occur if the query is in BATCH mode. This means that a Columnstore MUST be present somewhere in the query.
However, in SQL Server 2019 (currently in CTP 2.2), BATCH mode can be used without a Columnstore present. It is now viable for all (a lot of) iterators.
On my Surface, which I’m currently coding against, I don’t have 2019 installed and therefore to get the join to occur I’ve had to create a copy of my SalesOrderHeader table and columnstore it:
drop table if exists salesOrderHeader
go
select *
into salesOrderHeader
from AdventureWorks2012.sales.SalesOrderHeader
create clustered columnstore index ccix_salesHeader on salesOrderHeaderSo… now let’s run a query which has a large variance data (for which I’m using the query from the previous blog… linking Sales to SalesPersonID, but this time via a join because a direct query on the table no longer has the desired effect due to the Columnstore):
select SalesPersonID, TotalDue
from SalesOrderHeader s
join AdventureWorks2012.person.person p
on s.SalesPersonID = p.BusinessEntityID
where orderDate >= '2007-01-01'
and SalesPersonID >= 200
option (recompile)
And there we are… the Adaptive Join. So… what is it?
It’s basically BOTH a Nested Loop and a Hash join in one. What happens is that the Query Optimizer knows that there’s variance in the data and therefore it gives itself options by creating this execution plan, catering for both options in one.
What happens upon execution is that the query starts running without deciding which direction it’s heading… it reads records from the Input (ie. The columnstore in the plan above) and if it is happy there is only a few records coming out then it uses a Nested Loop… but if the stream of records coming in seems large, it uses the Hash.
This, therefore, attempts to remove our performance issues around parameter sniffing. It’s not perfect (the cutoff for choosing each option may not be perfect) but it does alleviate the problem to a large degree.
Couple of notes:
How do you know which has been used at execution time? The execution plan will let you know:
As per the above, you can see that the estimated plan was that it would use a Hash and, upon running, it did indeed use a Hash match.
Changing the query slightly will give us the other option:
select SalesPersonID, TotalDue
from SalesOrderHeader s
join AdventureWorks2012.person.person p
on s.SalesPersonID = p.BusinessEntityID
where orderDate >= '2007-01-01'
and SalesPersonID >= 290
option (recompile)
Bingo.
So, lastly… why is it that we can only see this join using Batch mode? It’s a logical answer actually… in Execution Plans, records are streamed one at a time (from right to left in the visual plan). Therefore it would be cumbersome to re-write the optimizer to work in a different way by streaming records until it could make a decision on the join type. However, in Batch mode SQL Server streams batches of rows (just under 1000 in each batch)… therefore just one batch and it can make a decent guess as to what choice to make. That fits with the way the Optimizer works… one single “GET” command to the first operator in the plan (from right to left again) and it can make a choice… no blocking and no heavy re-writes of internal Optimizer code.
Therefore we need Batch mode for this to appear. As mentioned, in SQL Server 2017 this requires a Columnstore, but in SQL Server 2019 this pretty much comes as standard.